iqtoolkit journal
PostgreSQL vs. MongoDB for JSON: The Internal Trade-offs They Don't Tell You in the Docs
The question comes up constantly in architecture discussions: "Should we use MongoDB or PostgreSQL for our JSON-heavy workload?" Having managed both at scale, I can tell you the answer is not as simple as "MongoDB is for documents, Postgres is for tables." There are deep internals at play on both sides that will affect your performance, storage footprint, and operational burden in ways that a quick benchmark won't reveal. Let's dig in.
First, a Fundamental Framing Problem
MongoDB is often called a "document database," which people interpret as: great for JSON, superior to relational databases for flexible data. That framing is misleading. MongoDB is not simply a JSON store with a query layer on top. It is a non-relational database, meaning it has no native concept of joins, no foreign key enforcement, no referential integrity, and no support for multi-document ACID transactions that span arbitrary collections (multi-document transactions were added in v4.0 but carry significant performance overhead and are not the default usage pattern).
To be precise for teams running MongoDB Atlas or Enterprise: while MongoDB does support multi-document transactions, they are bound by a 60-second execution limit and incur significant throughput penalties as lock contention increases. In PostgreSQL, a transaction is a first-class citizen — the default behavior for every statement. In MongoDB, a multi-document transaction is a specialized escape hatch you reach for when your schema design has failed to keep related data local to a single document. That distinction matters enormously at scale.
This matters because the moment your data has relationships — orders belong to customers, line items belong to orders, products belong to categories — MongoDB forces you to either embed everything (document bloat, duplication, update anomalies) or handle joins in application code ($lookup is available but is a post-processing aggregation step, not a query optimizer join). Neither is free. PostgreSQL's relational model with JSON support gives you both flexibility and the full power of set-based relational operations.
PostgreSQL's JSON Capabilities: More Than You Think
PostgreSQL has two JSON data types: json (stored as plain text, re-parsed on each access) and jsonb (stored as a parsed binary format, indexed, and operator-rich). For any production workload, use jsonb.
With jsonb you get:
- GIN indexes on the entire document or specific paths for fast containment queries (
@>operator) - Path-based expression indexes:
CREATE INDEX ON events ((payload ->> 'event_type')) - Full SQL: join your JSON documents against normalized tables, filter with CTEs, aggregate with window functions
- Partial indexes: index only the subset of rows where a JSON field meets a condition
- Schema validation via
CHECKconstraints on JSON paths when you need it
MongoDB also has rich query capabilities on nested documents, but it lacks the composability of SQL. Complex reporting that mixes document access with aggregation across related collections becomes an aggregation pipeline exercise that few SQL developers would recognize as readable.
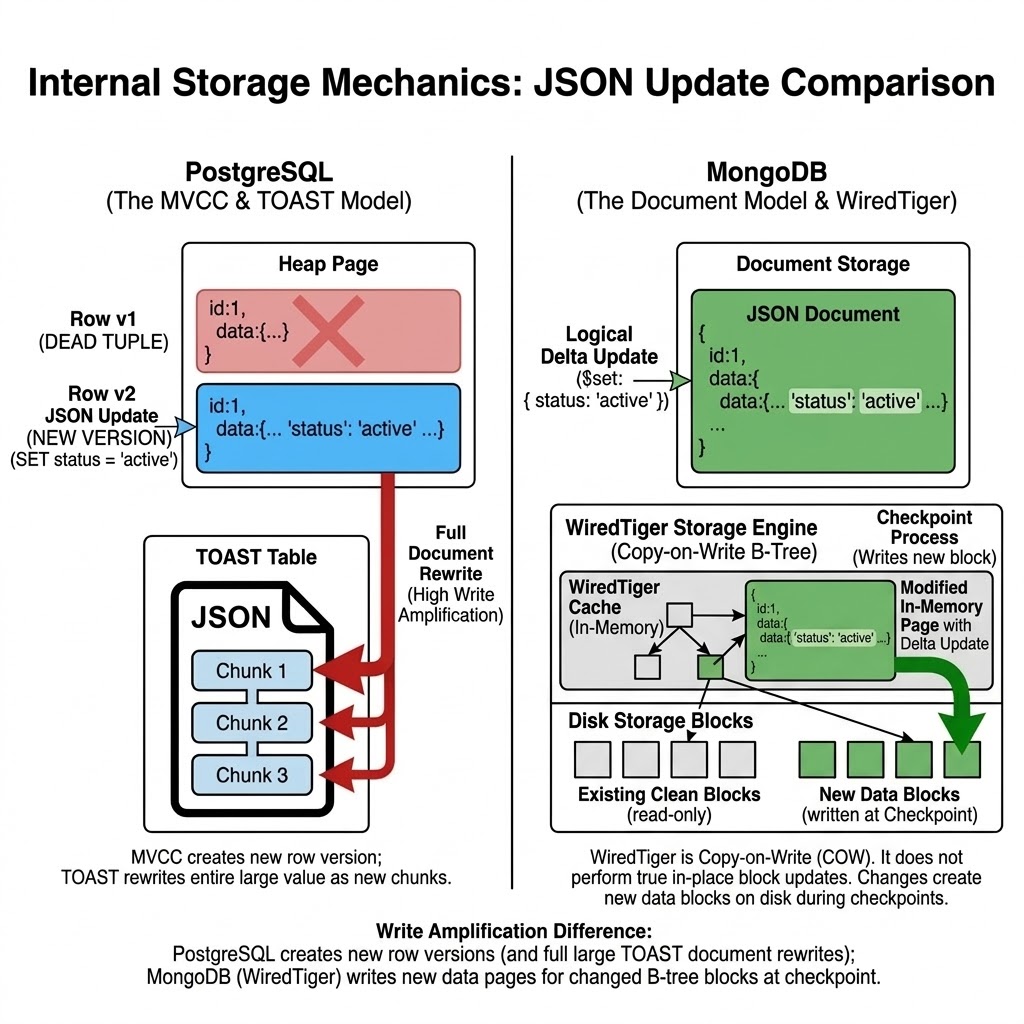
MVCC: The Hidden Cost in PostgreSQL JSON Workloads
PostgreSQL uses Multi-Version Concurrency Control (MVCC) to handle concurrent reads and writes without locking. The mechanics create a write amplification problem that is especially painful for large jsonb columns.
How MVCC works on an UPDATE:
BEFORE UPDATE:
[Heap Page]
+------------------------------------------+
| Tuple v1 (xmin=100, xmax=0) | ...data... |
+------------------------------------------+
AFTER UPDATE (change one JSON key):
[Heap Page]
+------------------------------------------+
| Tuple v1 (xmin=100, xmax=200) | ...data... | <-- marked DEAD
| Tuple v2 (xmin=200, xmax=0) | ...data... | <-- NEW full copy
+------------------------------------------+
^
Dead tuple occupies space until VACUUM runs
When you update a row, PostgreSQL does not modify the existing row in place. It writes a new version of the entire row and marks the old version as dead. Even if you change a single key in a 10KB jsonb document, the full 10KB is written again. Readers on older snapshots see the prior version until their transaction completes — which is excellent for read concurrency, but means dead tuples accumulate on disk.
For JSON-heavy workloads with frequent partial updates, this means:
- Table bloat builds faster than in equivalent workloads on narrow rows
- Index bloat follows, because index entries point to specific heap tuple versions
- Query performance degrades as the visibility map becomes stale and more pages need checking
MongoDB's WiredTiger storage engine also uses MVCC internally, but it employs a copy-on-write B-Tree model rather than PostgreSQL's heap-based tuple versioning. When you update a document, WiredTiger caches the modification in memory and appends it to a Write-Ahead Log. During its periodic checkpoint process, it writes modified pages to new block locations on disk and eventually frees the old space.
While WiredTiger avoids the exact single-row write amplification seen in PostgreSQL, it is not zero-cost. It still involves writing out entire compressed pages during checkpoints, and relies heavily on background cache eviction to maintain performance.
VACUUM: PostgreSQL's Maintenance Obligation
VACUUM is PostgreSQL's answer to MVCC dead tuple accumulation. It reclaims space occupied by dead tuples, updates the visibility map (allowing Index-Only Scans to skip heap fetches), and prevents transaction ID wraparound — the catastrophic failure mode where Postgres refuses to accept new transactions.
PostgreSQL has autovacuum, a background daemon that triggers based on a dead tuple threshold (autovacuum_vacuum_scale_factor defaults to 20% of table size). For large tables, this default is dangerously high — a 500 million row table would need 100 million dead tuples before autovacuum wakes up.
For JSON-heavy workloads, tune aggressively:
- Lower
autovacuum_vacuum_scale_factorto0.01or even0.005for large tables - Raise autovacuum's I/O budget by reducing
autovacuum_vacuum_cost_delay - Monitor
pg_stat_user_tables: trackn_dead_tup,last_autovacuum, andlast_autoanalyze - Consider
VACUUM ANALYZEafter bulk loads or mass updates to refresh planner statistics
MongoDB does not have an equivalent to VACUUM. WiredTiger reclaims space within its B-tree pages automatically via checkpointing, and collection-level compaction can be triggered manually. There is no "transaction ID wraparound" risk, and space reclamation is generally more transparent to the application.
TOAST: PostgreSQL's Large Value Storage
PostgreSQL has a hard limit: a single row must fit on one 8KB page. Since jsonb documents can easily exceed 8KB, PostgreSQL uses TOAST (The Oversized-Attribute Storage Technique) to handle large values.
When a jsonb value exceeds roughly 2KB (the TOAST threshold), PostgreSQL will automatically:
- Compress the value (using LZ compression by default)
- If still too large, chunk it into 2KB segments stored in a separate TOAST table (
pg_toast_<oid>) - Store a pointer in the main heap row referencing the TOAST chunks
This is largely transparent, but the performance implications are real:
- Reads: fetching a TOASTed column requires an additional heap scan on the TOAST table — extra I/O on every large document fetch
- Updates: updating any field in a large
jsonbdocument causes the entire value to be re-TOASTed, even if you only changed one key. Combined with MVCC write amplification, this is double the I/O penalty - VACUUM on TOAST tables: autovacuum must process the TOAST table separately; TOAST table bloat is a common source of hidden disk usage that operators miss
- Index access: GIN indexes on
jsonboperate on the decompressed value, so retrieving the full document still requires a TOAST table hit, even if the query filter was satisfied entirely by a GIN index
The practical recommendation: if your JSON documents regularly exceed 4–8KB, consider splitting large, rarely-queried fields into separate columns or an object store. Keep the frequently-queried JSON fields in a compact jsonb column.
MongoDB documents have their own size limit (16MB per document) and store data in BSON format. WiredTiger handles variable-length documents natively without a separate overflow mechanism, which gives MongoDB an advantage for workloads dominated by large, frequently-updated documents.
The Decision Framework
PostgreSQL (jsonb)
- Transactions: ACID by default for every statement
- Joins: native SQL joins with optimizer support
- Integrity: foreign keys and relational constraints
- Update write cost: full-row rewrite on updates
- Large JSON reads: TOAST can add extra I/O on large values
- Space maintenance: requires VACUUM tuning on write-heavy workloads
- Index options: GIN, B-tree, partial, and expression indexes
- Analytics: full SQL, CTEs, and window functions
- Best fit: mixed relational + JSON workloads
MongoDB
- Transactions: multi-document ACID available, but with higher overhead
- Joins:
$lookupas an aggregation stage - Integrity: no native relational integrity model
- Update write cost: copy-on-write page checkpointing in WiredTiger
- Large JSON reads: BSON inline storage up to 16MB document limit
- Space maintenance: automatic space reuse, optional manual compaction
- Index options: compound, multikey, text, and geospatial indexes
- Analytics: aggregation pipeline model
- Best fit: document-first workloads
The Operational Reality
In my experience managing both at scale, PostgreSQL's MVCC + VACUUM model requires more active DBA engagement for write-heavy JSON workloads. You will fight bloat if you don't tune autovacuum aggressively. TOAST adds I/O overhead that isn't obvious until you instrument it. But the payoff — full SQL expressiveness, relational integrity, and a single database for everything — is significant.
MongoDB's operational model is simpler for pure document workloads, but the moment your product evolves and relationships emerge (they always do), you pay the cost of having chosen a non-relational foundation at a time when re-architecting is expensive.
The best database for JSON is the one you understand deeply enough to tune, monitor, and operate at production scale. For most teams building data-intensive applications in 2026, that database is PostgreSQL.
One contender I haven't covered here is Amazon DocumentDB — a MongoDB-compatible service built on the Aurora storage layer that deserves its own deep dive. I'll be publishing a follow-up post that adds DocumentDB to the mix, including what it actually is under the hood, where it diverges from native MongoDB, and how it stacks up against Aurora PostgreSQL for JSON workloads on AWS.
Have you run into TOAST bloat or MVCC write amplification in a PostgreSQL JSON workload? Or migrated from MongoDB back to Postgres? Drop a comment — I'd love to compare notes.